Keyboard Controls: W/S - Move Forward/Backward ↑↓←→ - Rotate Camera +/- - Adjust Input Views





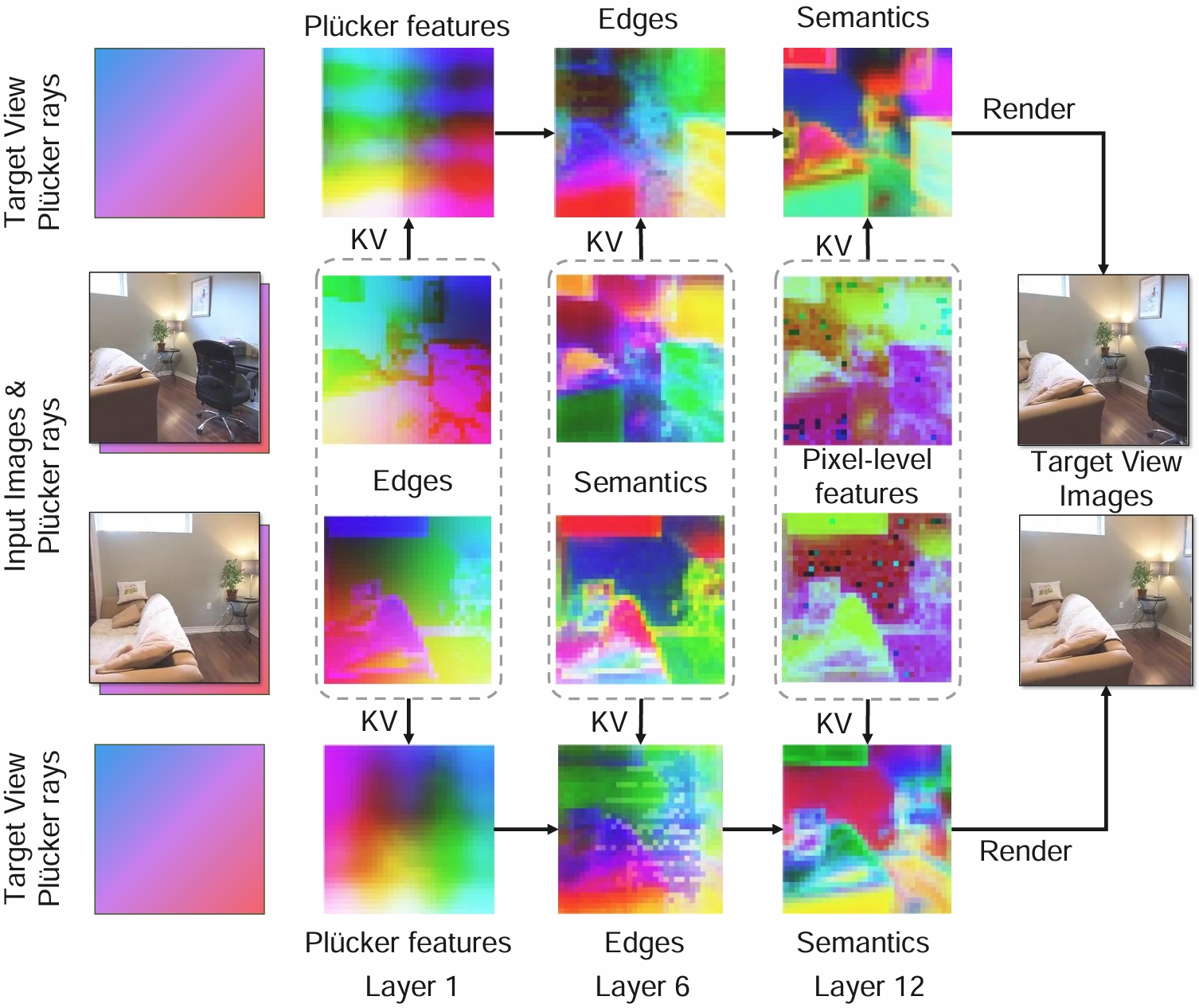
PCA Visualization of Input and Target Views Features at Different Layers.
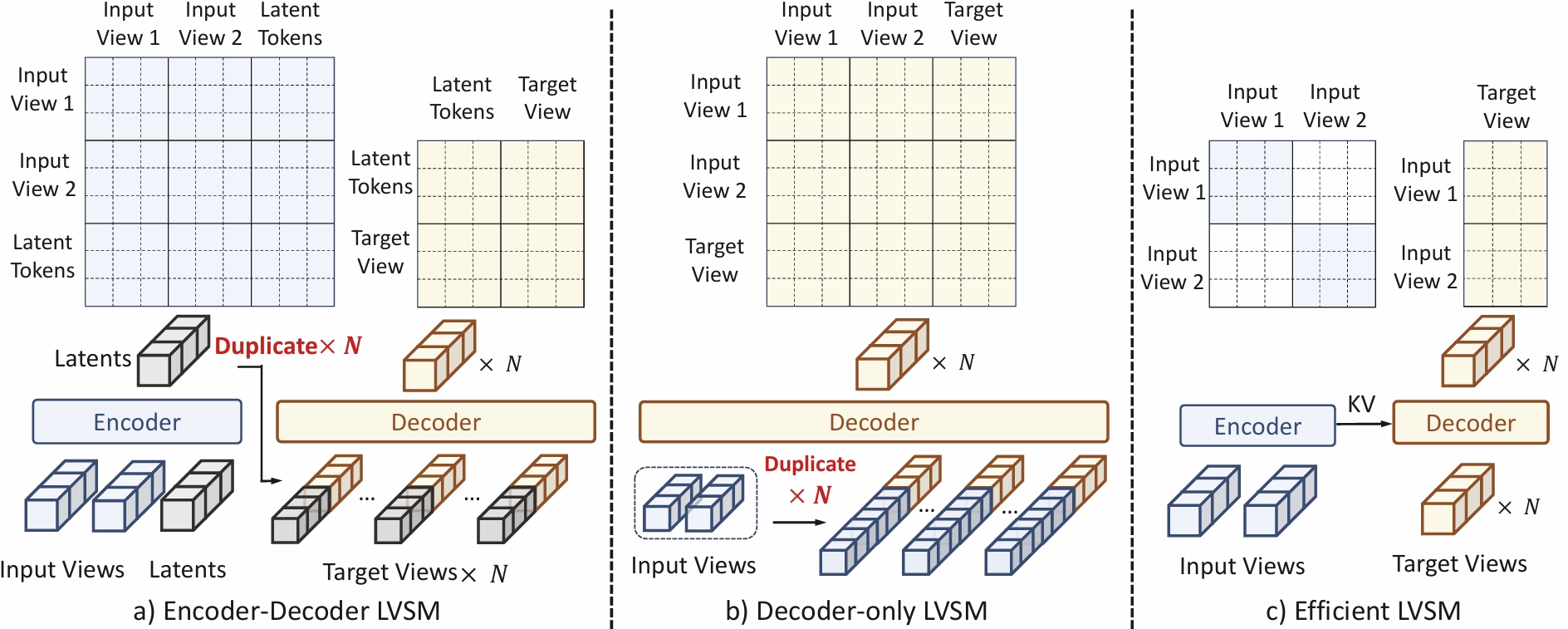
Latent Novel View Synthesis Paradigms Comparison. The proposed decoupled architecture disentangles the input and target streams. It maintains the integrity and specialization with high efficiency, obtaining better rendering quality and faster inference speed.
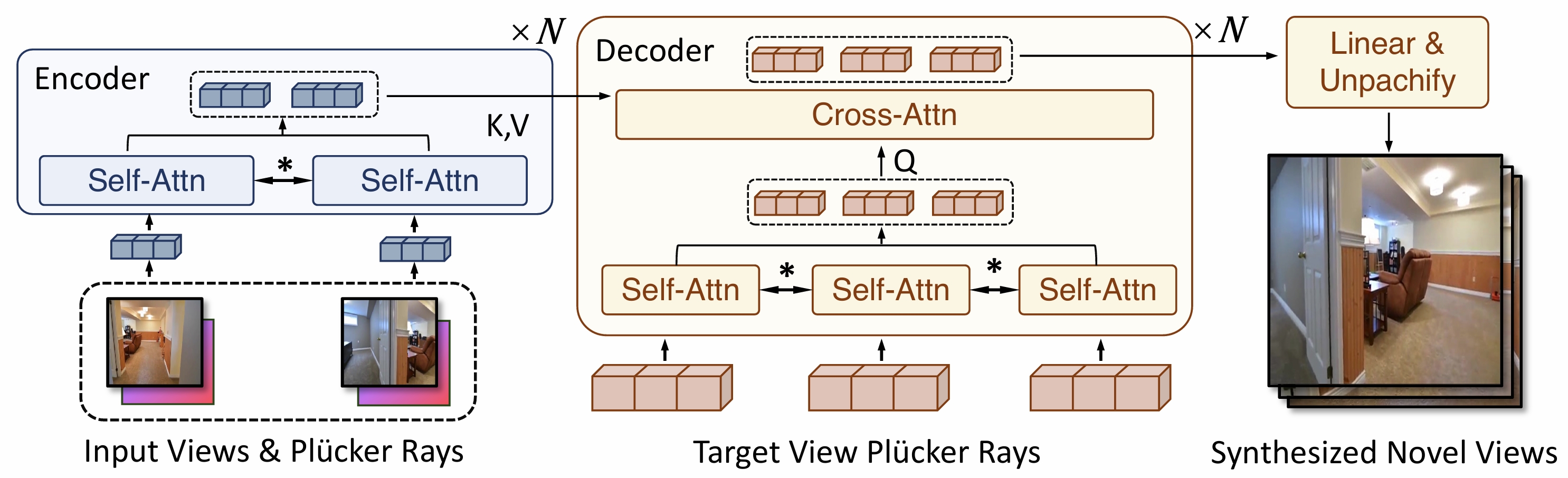
Efficient-LVSM Model Structure. Efficient-LVSM patchifies posed input images and target Plücker into tokens. Tokens of each input view separately pass through an encoder to extract contextual information. Target tokens self-attend to input tokens and then cross-attend to render new views.
@article{jia2025efficientlvsm,
title={Efficient-LVSM: Faster, Cheaper, and Better Large View Synthesis Model via Decoupled Co-Refinement Attention},
author={Jia, Xiaosong and Sun, Yihang and You, Junqi and Wong, Songbur and Zou, Zichen and Yan, Junchi and Wu, Zuxuan and Jiang, Yu-Gang},
journal={International Conference on Learning Representations (ICLR)},
year={2026}
}
